生成 AI に関する話題の中で、RAG という言葉がよく出てきますよね。ただ、言葉としては聞いたことがあっても、実際のところどのようなものなのかがあまり具体的にイメージできていない人もいるのではないでしょうか。
今回は、簡単な RAG を作ってみることで、より具体的な理解ができるようになることを目指してみます。
RAG(Retrieval-Augmented-Generation)とは
RAG の目的
RAG が具体的にどんなことをやっていくのかを見ていく前に、RAG がどのような目的で使われる手法なのかを考えてみます。
ChatGTP などの LLM は一般的な情報を使って学習したモデルであるため、インターネット上に情報の少ない内容だったり、社内のナレッジベースなどのクローズドな情報であったり、モデルが学習したときには無かった新しい情報といったものには、精度の高い回答ができません。
しかし LLM の持っている、人間の書いた文章の内容から回答を作成する能力を、自社の業務やサービス、自分のオリジナルなアプリなどに使おうとすると、多くの場合に、上記のような情報を含めた回答を生成してほしくなりますよね。
RAG を 「LLM(大規模言語モデル)に特定の知識・情報について精度の高い回答させたい」 という目的を達成するために使われる手法として認識しておくと、この後も理解が進みやすいのではないかと思います。
RAG の特徴
いろいろなページで(例えばAWS のページなど)で RAG について書かれていますが、おさえておくべき特徴としては以下のような感じでしょうか。
LLM 自体のモデル調整はしない
ファインチューニングなどモデル自体を特定の知識に対して強化・調整する方法はありますが、RAG の場合にはそれは行いません。
- 情報を増やすたびにモデルの学習をしなくて良い
- モデルの学習をするためのコンピューティングリソース(学習コスト)が要らない
という点が、日々追加・変更のある社内のドキュメントをであったり、最新の情報を常時追加していくようなケースで、使いやすい点になると思います。
LLM に対して追加の情報を与えて生成させる
モデルを調整せずにどうするのかというと、特定の情報についての回答を生成させるのに必要な情報を付与した上で、LLM に回答を指示します。
例えば SUPINF の会社の情報は LLM のモデルに入るほどは一般的な情報ではないかもしれませんが、SUPINF について書かれた文章を追加情報として与えた上で回答を指示することで、正しい回答をさせるようなイメージです。
LLM への回答作成の指示は(RAG 以外で使うときと同様に)プロンプトを与えるという方法なので、ここでは、どのようなプロンプトで質問と追加情報を渡していくと良い精度の回答が生成されるのか、という工夫が必要になってきそうです。
質問から情報を検索する仕組み
追加情報が一度に LLM に渡せるくらいの情報であれば、毎回渡してしまっても良いのかもしれませんが LLM のプロンプトに入力できる文字数には限界があります。社内のナレッジだったり、多くのケースでは、必要な情報はもっとずっとたくさんあるはずです。
では「SUPINF でキャンプが好きなのは誰ですか?」という質問から、LLM に与えるべき追加情報となる情報を準備するにはどうすれば良いのでしょうか。質問をもとに、それに回答するために必要になるであろう情報を、社内のナレッジなどのデータの中から、抽出してくる必要があります。(RAG の「Retrieval」に当たる部分ですね)
この部分には、RAG についての記事を見ると Vector Database が使われていることが多く、質問とドキュメントの類似度によって検索してくるパターンが今は主流のようです。
ここまでをまとめると
- LLM に特定の知識・情報について精度の高い回答させたい
- そのために、LLM に、質問と一緒に追加情報を渡して回答させたい
- しかし全部の情報は渡せないので、質問と関連性の高い情報をいい感じに抽出したものを渡す
といった感じになるでしょうか。
Knowledge Base for Amazon Bedrock を使ってみる
実際に、Knowledge Base を使って、やってみましょう。
東京リージョンではまだサポートされていなかった
私が試した時点では Knowledge Base はまだ東京リージョンでは対応していなかったため、オレゴンで試しました。Knowledge Base 以外にも Bedrock のメニューを比べてみると東京とオレゴンでは結構差があるように見えました。
Knowledge Base で設定するもの
以下は Knowledge Base でデータが処理される仕組みを、私なりにまとめてみた図です。 基本的には、データソース、埋め込みモデル、ベクトルデータベースを設定することになります。
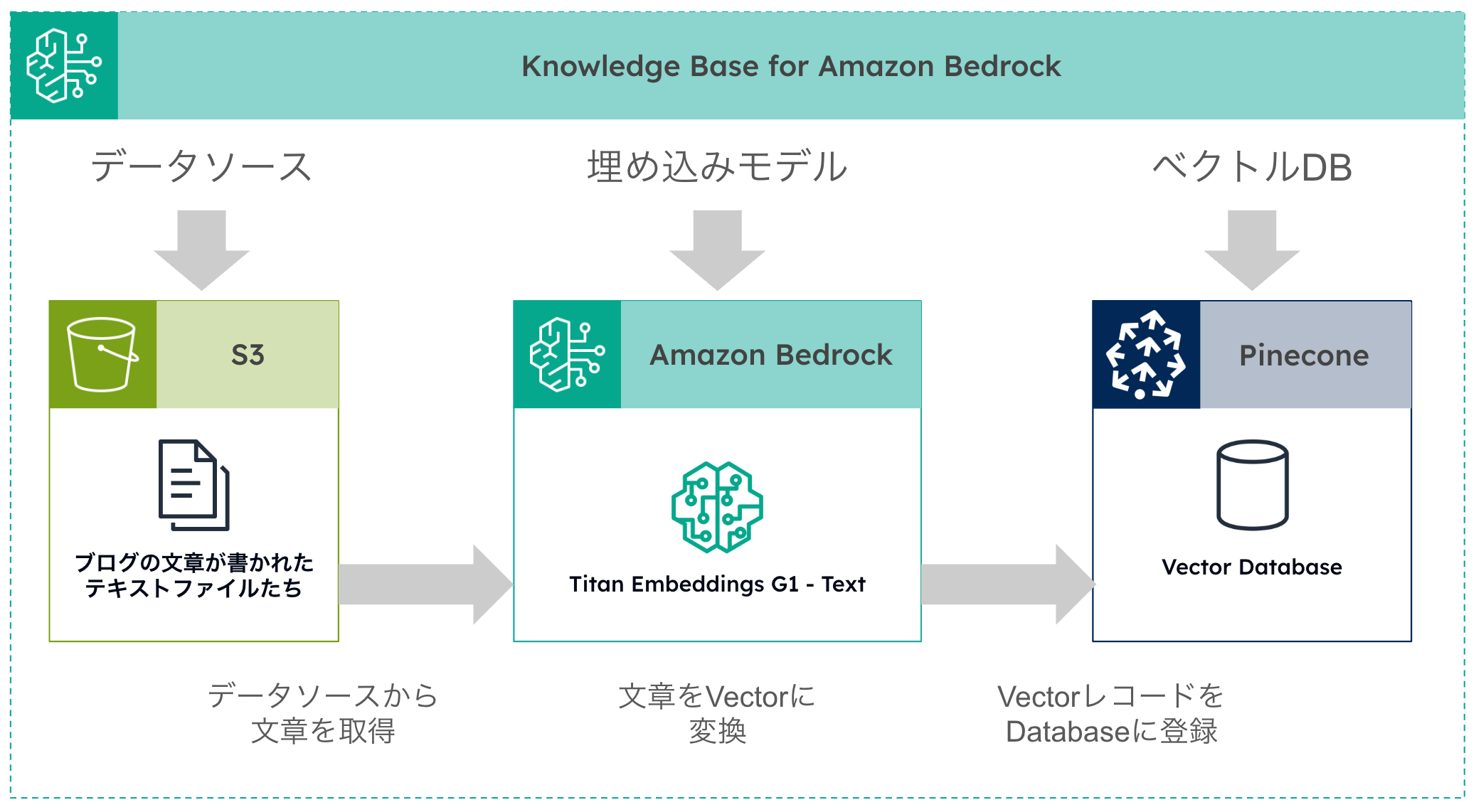
回答させたい分野のデータを準備する
今回は、SUPINF のブログの文章をテキスト化したものをデータとして使ってみました。
現時点ではデータソースの場所としては S3 のバケットだけが使えるようですので、作成したファイルを S3 にアップロードし、そこをデータソースにするよう指定しました。
埋め込みモデルを選択する
埋め込みモデルは、元情報の文章を、ベクトル情報に変換するためのモデルです。詳細はここでは書ききれなそうなので OpenAI のページなどを読んでいただければと思いますが、このページの中にも、
"embedding": [
-0.006929283495992422,
-0.005336422007530928,
...
-4.547132266452536e-05,
-0.024047505110502243
]
のような部分があり、文字列が実際にベクトルの形式に変換される感じが分かるのではないかと思います。不定形で規格の無い元の文章の状態から、決まった要素数のベクトルの形式に変換しておくことで、今回やるような類似度の計算など、計算という形で処理しやすくなるということなのですね。
今回は、 Titan Embeddings G1 - Text v1.2 を選択しました。
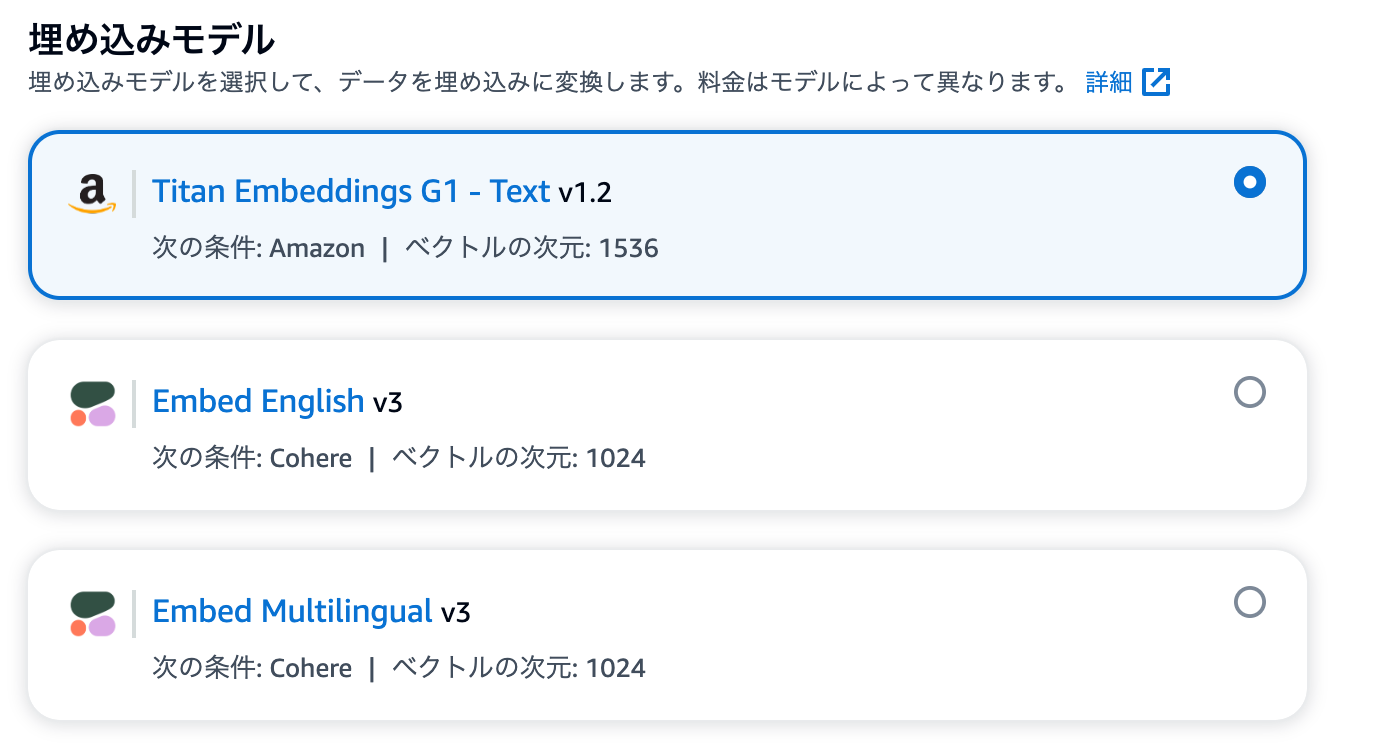
ベクトルデータベースとして Pinecone を使ってみる
埋め込みモデルによって変換されたベクトルのレコードは、ベクトルデータベースに保存します。

選択肢はいくつかあるのですが、Pinecone には無料で使える枠があり、他の選択肢と比べて安く試せそうだったので使ってみることにしました。
Pinecone へのサインアップ手順などはここでは省略しますが、以下のように Pinecone 側でTitan Embeddings G1 - Text v1.2と同じ Dimensions 数(1536)でベクトルデータベースを作成しました。
Pinecone 側でデータベースを作成するとエンドポイントが作成され、また API キーも発行できますので、それらの値を Knowledge Base 側で使えるように設定します。
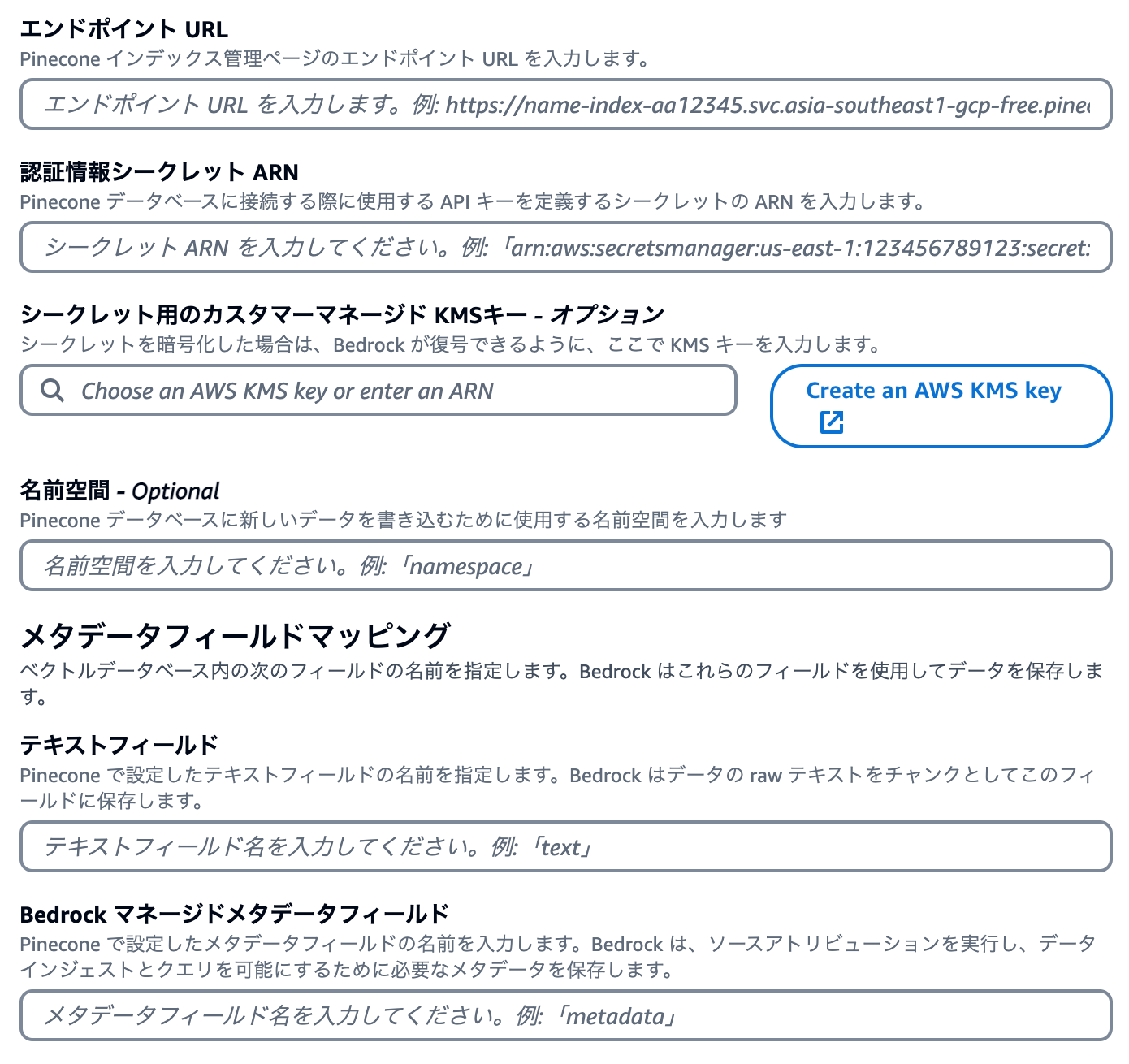
このとき、SecretsManager に API キーを登録する必要があるのですが、その時のキーは私が試したときには apiKey にする必要があるようでした(プレーンテキストで表示すると {"apiKey":"xxxx-xxxx-xxxx-xxxx"}のようになる)。そのことが登録中の画面からは分からなかったので少しハマりました。
Knowledge Base の同期(Sync)を実行してみる
ベクトルデータベースの設定まで終わったら設定が完了し、以下のように Knowledge Base が作成されます。
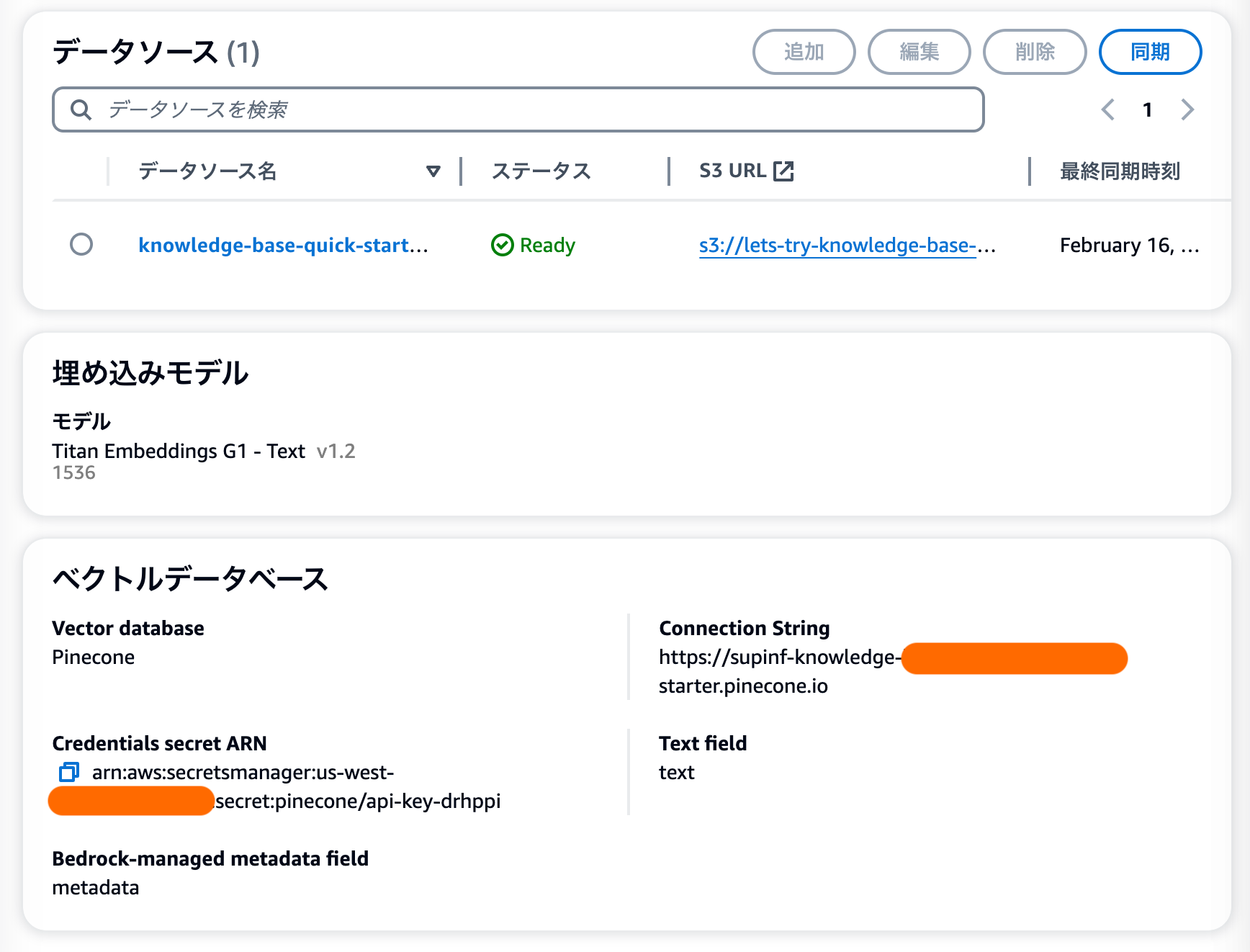
この画面の右上にある「同期」というボタンをクリックすると、以下の再掲図にあるように
- データソースから文章を取得
- 埋め込みモデルを使ってベクトルに変換
- ベクトルデータベースに登録
という処理が実行されます。
同期が完了したらベクトルデータベースを見てみます。
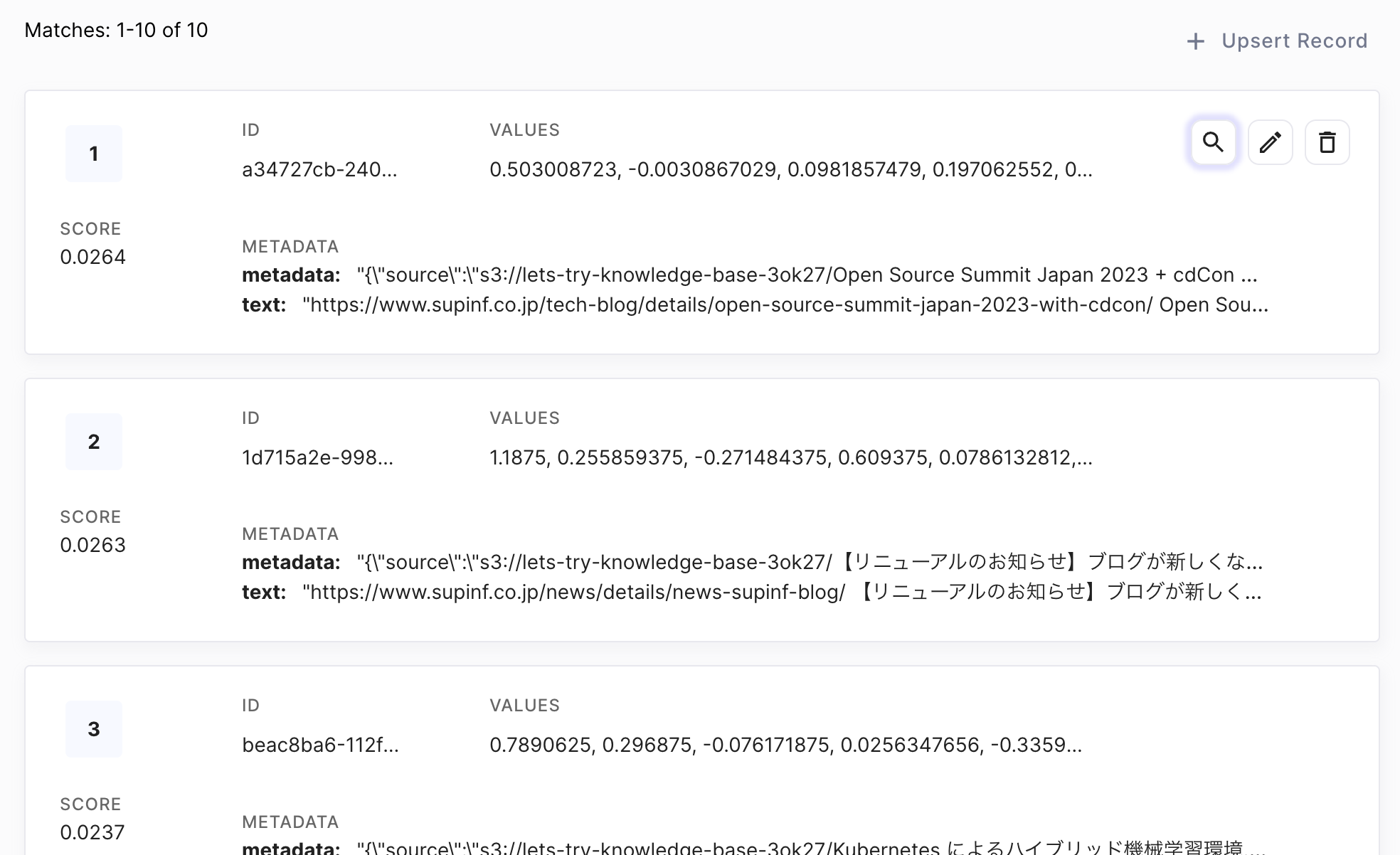
ベクトル部分は千個以上の数値の羅列なので人間には理解することは難しいですが、レコードが入っていることは確認できました。
RAG を使って回答を生成してみる
今回 RAG 用のデータとして使った SUPINF のブログの情報から分かる質問の例として
「SUPINF でキャンプが好きなのは誰ですか?」
という質問をしてみましょう。
まずは、ChatGPT に同じ質問をしたときの結果を見てみましょう。

結果はうまく返ってきません。一般的な LLM のモデル単体ではこの質問には正しく回答できないと思います。これは企業が社内で持っているような情報でも同様ですね。
次に、今回 RAG を構築した Knowledge Base のテスト機能を使って質問をしてみます。LLM モデルは、日本語の性能が良さそうな Claude を選択してみました。
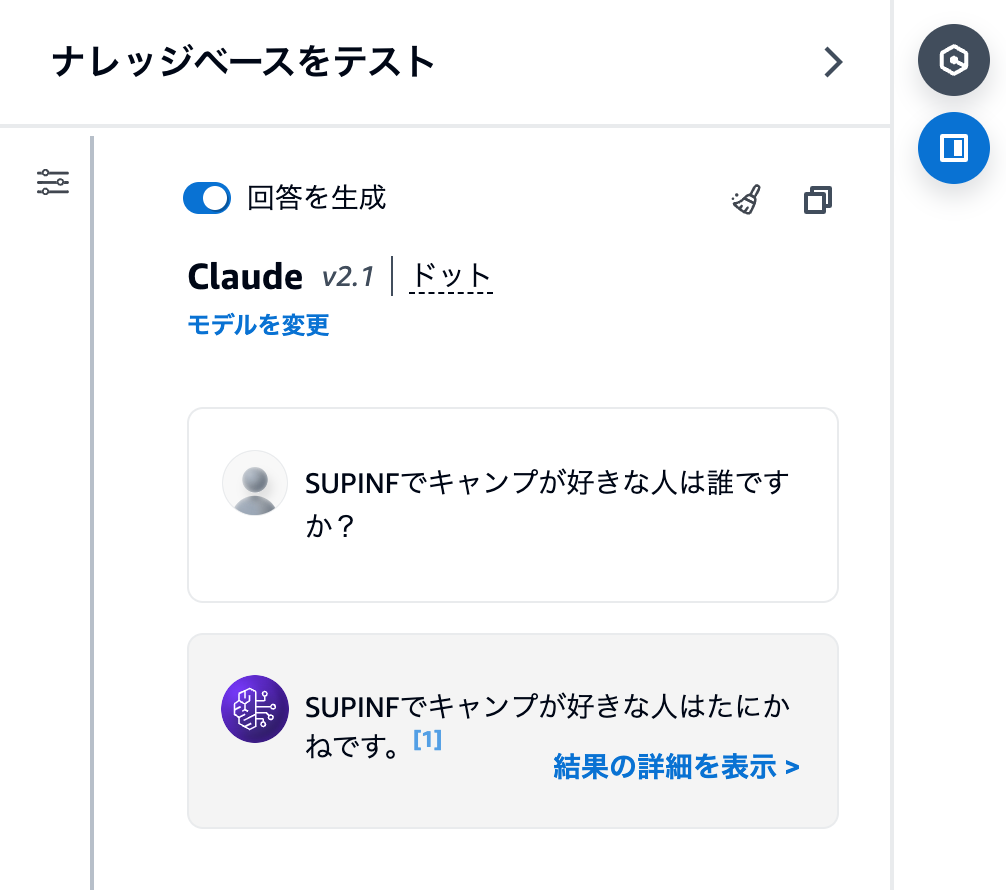
この記事の内容をもとに、正しい回答が作成されました。「結果の詳細を表示」というところをクリックしてみると、
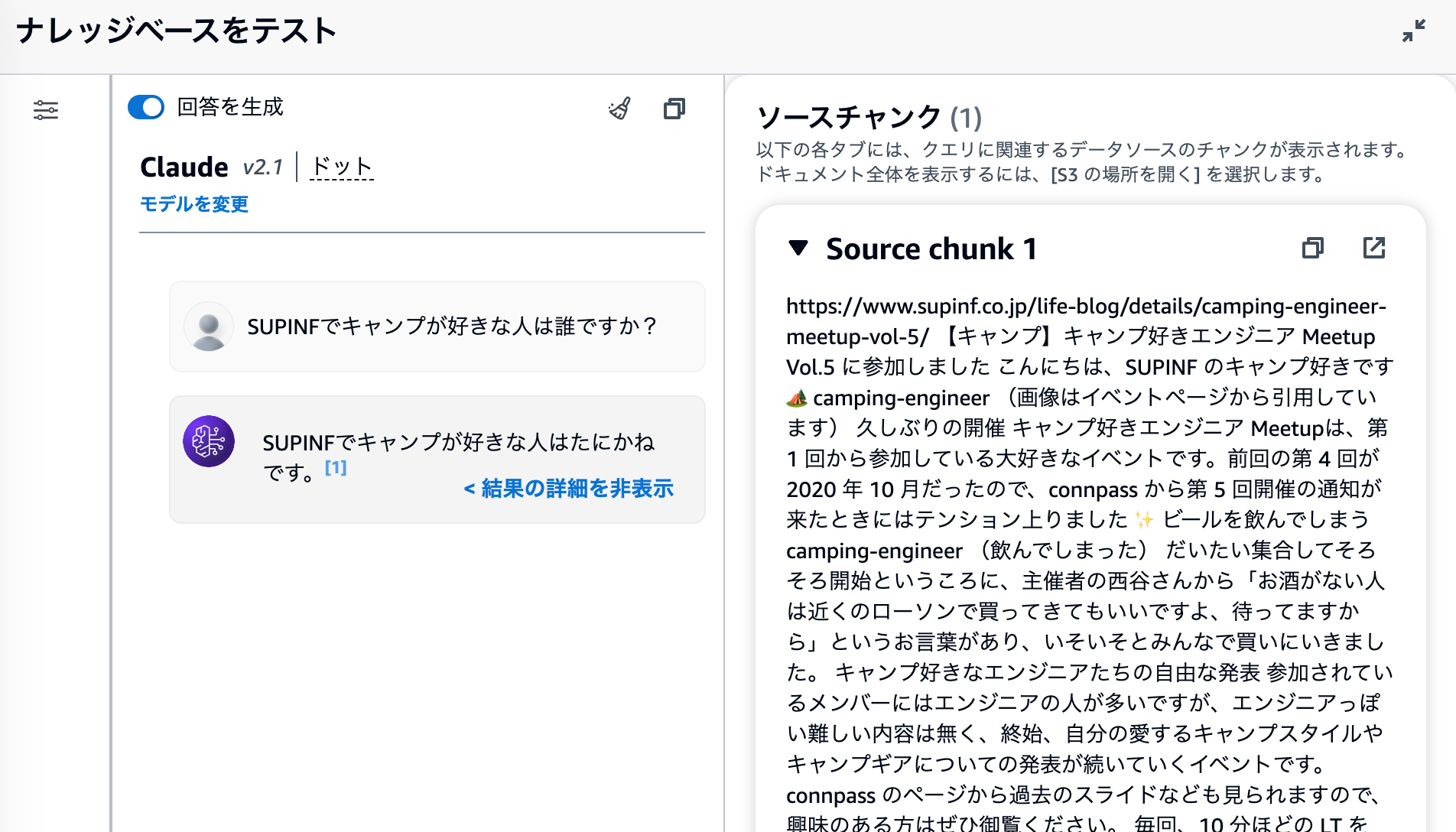
ソースチャンクというのが出てきます。質問の文章と関連性の高いベクトルデータベースのレコードが検索されて、その情報を LLM に追加情報として渡して回答を生成させているということなのですね。
このときの仕組みを以下に図にまとめてみました。
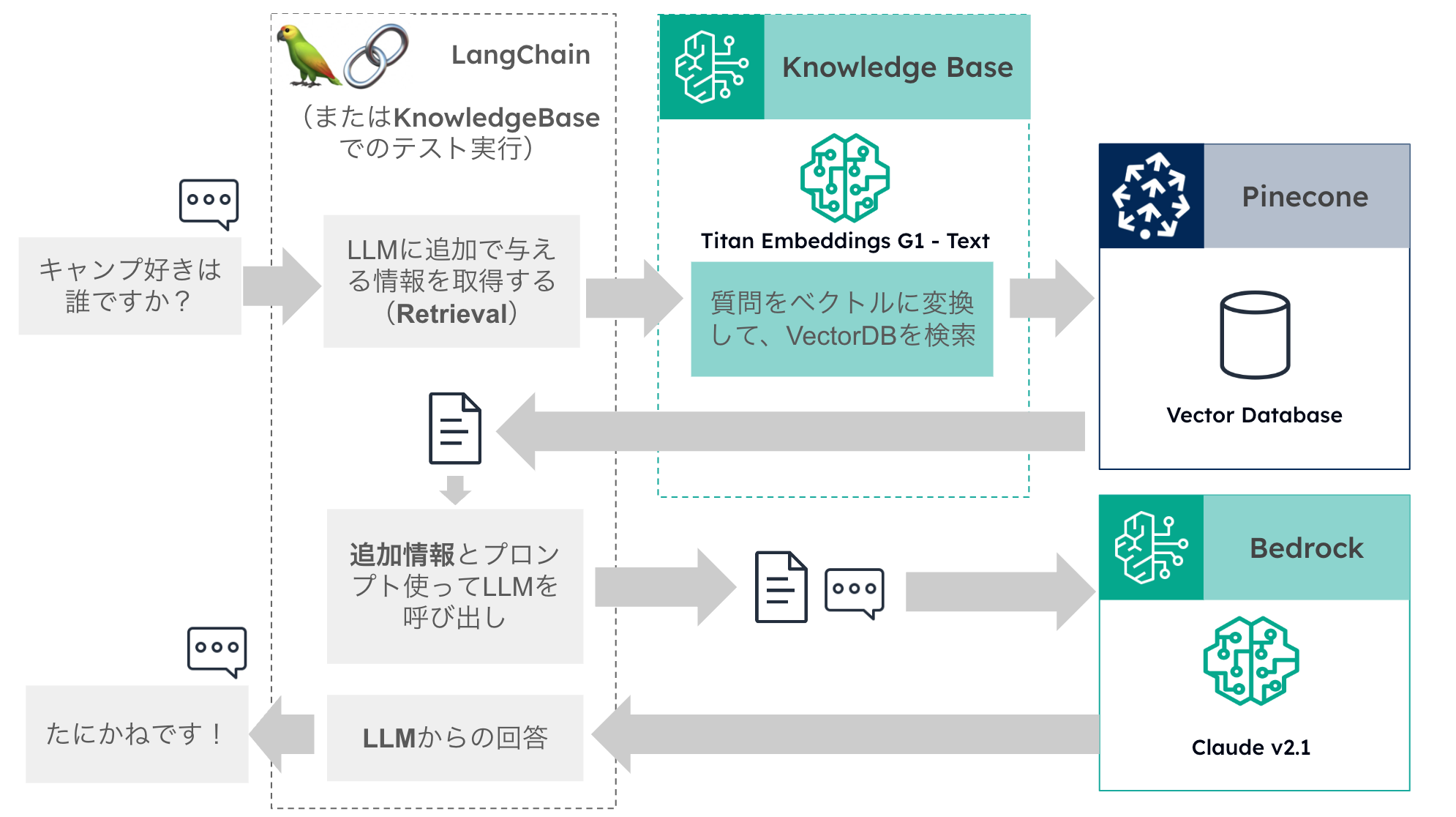
- 質問を、埋め込みモデルを使ってベクトル化する
- 質問のベクトルを使ってベクトルデータベースに問い合わせることで、質問と関連性の高い文章を取得できる
- 質問と、2 で取得した情報の両方を使って LLM(この場合には Claude2.1)に回答を生成させる
ということをしています。
データソースを用意したりベクトルデータベースにデータを登録したりという実際のナレッジを処理する部分と、LLM モデルを呼び出す部分は割と独立して扱えそうです。より良いモデルが出てきた場合に、LLM モデルを切り替えて使うこともできそうですね。
課題
「SUPINF でキャンプが好きなのは誰ですか?」
という質問には正しく回答が生成されましたが、同じ答えになりそうな少し違った質問、
「SUPINF でテントを買いそうな人は誰ですか?」
にすると、回答できませんでした。
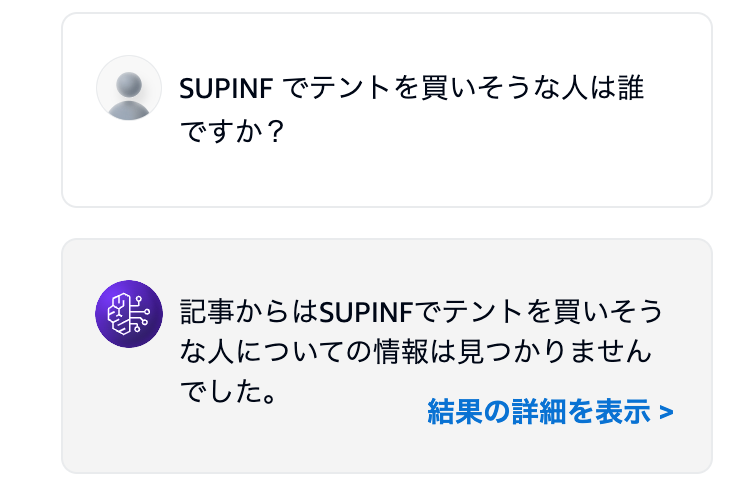
LLM モデルに渡される情報の中にキャンプについての情報が入っていれば、テントを解釈して回答することができると思いますが、ベクトルデータベースから情報が抽出できなければ、LLM にその情報が渡されることはなく、回答はできません。
- どのくらいの関連度までのデータをベクトルデータベースから取得するのか
- どのくらいの量のデータをベクトルデータベースから取得するのか
- どのくらいの文量を LLM に追加情報として渡すのか
- 取得したデータが多かった場合、どれを優先して LLM に渡すのか
といった部分のパラメータ等を今回は何も考慮していませんが、データソースからの情報抽出ができるかどうかがこの仕組みの肝となる部分なので、そこをもう少し詳しくやっていく必要がありそうです。
今回、手を動かして作ってみることで RAG の大まかな仕組みについては理解できてきたので、今後は抽出部分の精度を上げていく部分や、実際のサービスに組み込んでいく部分などについて、また試していこうと思います。
おわり。