生成 AI 技術は、近年目覚ましい進化を遂げています。
(今回の話に直接は関係ないですが、直近だと OpenAI の Sora の発表はかなり衝撃的だったのではないでしょうか)
これに伴い、周辺のエコシステムも継続して発展し続けており、新しいアプリケーションの開発や既存サーピスの強化として LLM を組み込むことも増えてきました。
このような環境の中で、LLM を活用したアプリケーションをより効率的に評価し、改善するためのツールが求められています。
そこで今回は、LLM を使ったアプリケーションを評価するための OSS である promptfoo を紹介します。
概要
promptfoo は LLM の出力品質を評価するための CLI およびライブラリです。
試行錯誤ではなくテスト駆動で LLM アプリケーションを開発することを目標としており、事前定義されたテストケースを使用してプロンプトや RAG アプリケーションなどを体系的にテストすることが可能となっています。
使い方 (CLI)
まず初めに、CLI の使い方について紹介します。
1. プロジェクトの初期化
以下のコマンドを実行することで、promptfooconfig.yaml(テストケースの定義ファイル) が生成されます。
# npm を使った場合
npm install -g promptfoo
promptfoo init
# npx を使った場合
npx promptfoo@latest init
2. テストケースの定義
生成された promptfooconfig.yaml にアプリケーションに沿ったテストケースを記述します。
定義例
description: Simple
# 評価するプロンプト
# 定義方法: https://www.promptfoo.dev/docs/configuration/parameters
prompts:
- Write a tweet about {{topic}}.
- Write a funny tweet about {{topic}} with the prerequisite that it be no more than 140 characters (including spaces and symbols).
# 構成ファイルからの相対パスでファイル(.txt, .json, .yaml, etc...)を指定することもできる
# - path/to/prompt.json
# 使用するプロバイダ
# 定義方法: https://www.promptfoo.dev/docs/providers
providers:
- id: openai:gpt-3.5-turbo
config:
temperature: 0
- id: openai:gpt-4
config:
temperature: 0
# プロバイダを自作することも可能となっているため、これを利用して RAG アプリケーションなどの評価を行うこともできる
# - id: python:custom_provider.py
# config:
# additionalOption: 123
# テストケース
tests:
# prompts や assert.value で利用する変数の定義
- vars:
topic: AWS, Google Cloud and Azure
max_length: 140
# アサーションの定義
# 定義方法: https://www.promptfoo.dev/docs/configuration/expected-outputs/
assert:
# 事前定義された評価方法を利用できる
# アサーションの種類: https://www.promptfoo.dev/docs/configuration/expected-outputs/#assertion-types
- type: icontains-all
value:
- AWS
- Google Cloud
- Azure
# JS や Python を利用して評価方法を定義することもできる
- type: javascript
value: '[...(new Intl.Segmenter("ja", { granularity: "grapheme" })).segment(output)].length <= context.vars.max_length;'
# 別の LLM を使用して出力結果を評価することもできる
# アサーションの種類: https://www.promptfoo.dev/docs/configuration/expected-outputs/model-graded
- type: llm-rubric
value: ensure that the output is funny
上記のほか、全てのテストケースに assert を適用するための defaultTest や、再利用可能なようにするための $ref、シナリオを記述するための scenarios などもサポートされているので、詳しくは公式ドキュメントを参照してください。
公式の Guides や examples もとても充実しているので、こちらも見てみてみると良いかもしれません。
3. 評価の実行
a. 環境変数の設定
実行前に、利用するプロバイダに応じて必要な環境変数を設定する必要があります。
例えば、OpenAI API を利用する場合は以下を設定する必要があります。
export OPENAI_API_KEY=your_api_key_here
b. 評価の実行
環境変数の設定が完了したら、以下のコマンドで評価を実行してみましょう。
# npm を使った場合
promptfoo eval
# npx を使った場合
npx promptfoo@latest eval
評価結果がターミナル上に表示されると思いますが、以下のコマンドでブラウザから確認することもできます。
# npm を使った場合
promptfoo view
# npx を使った場合
npx promptfoo@latest view
評価結果は以下の画像の通り、prompts, providers, tests の組み合わせを網羅した結果をテーブル形式で見ることができます。
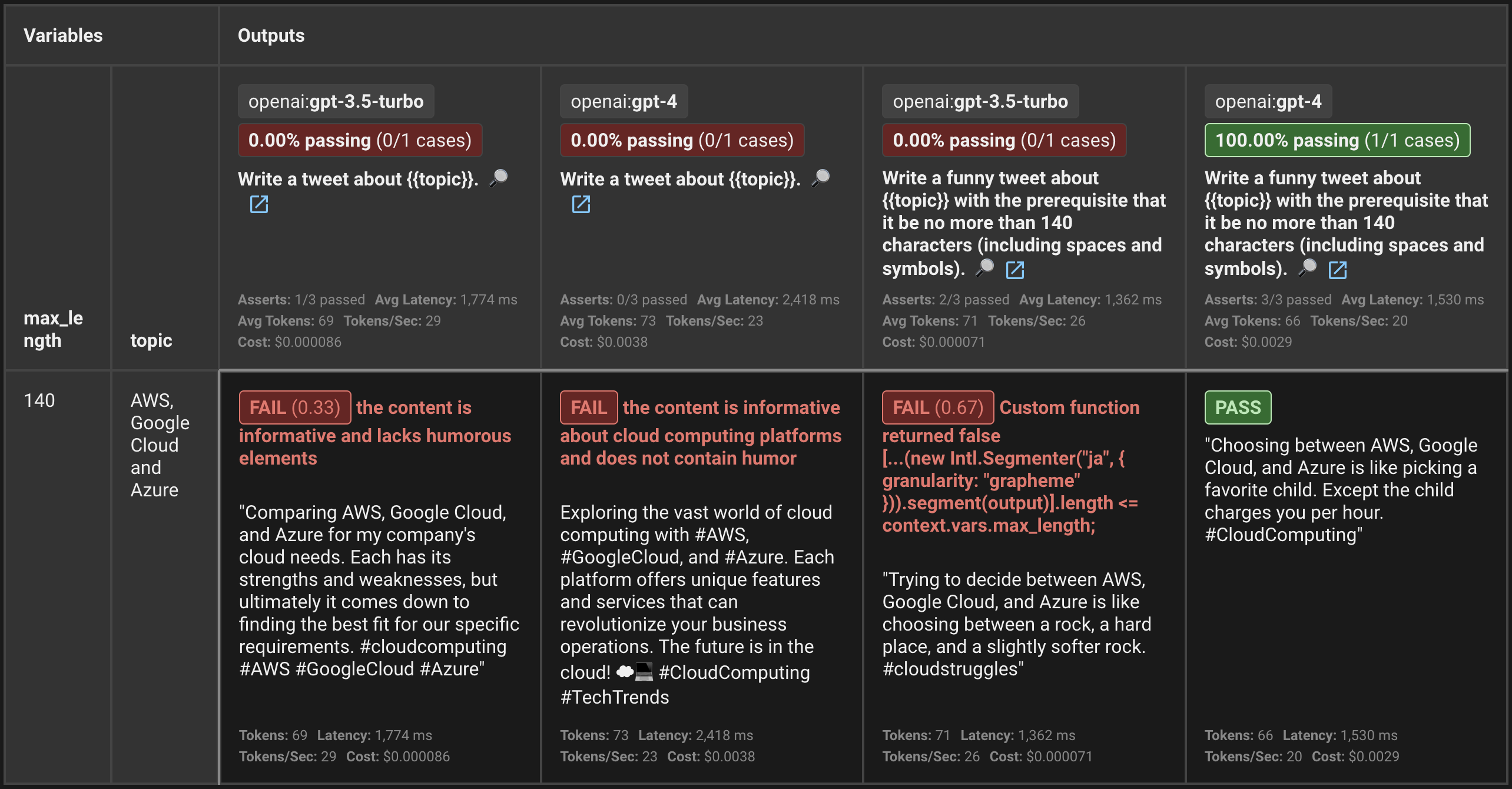
この場合、Write a funny tweet about AWS, Google Cloud and Azure with ... というプロンプトで gpt-4 を利用した場合のみすべてのテストケースが通っていることが分かります。
(gpt-3.5-turbo だと 140 文字という細かい指定が上手いこと処理されないことが分かって面白いですね)
コストやレイテンシーなどの情報を一括で見ることができるのも嬉しいポイントではないでしょうか。
c. キャッシュ管理
LLM プロバイダの API 呼び出し結果はデフォルトでキャッシュされます。
以下のコマンドを実行することでキャッシュを削除することができます。
# npm を使った場合
promptfoo cache clear
# npx を使った場合
npx promptfoo@latest cache clear
また、eval コマンド実行時に --no-cache オプションをつけるか、構成ファイルに { evaluateOptions: { cache: false } } を設定することでキャッシュを無効化することもできます。
4. 評価の共有
以下のコマンドを実行することで、評価結果を共有するための URL を発行することができます。
# npm を使った場合
promptfoo share
# npx を使った場合
npx promptfoo@latest share
ただし、URL を知っている人であれば誰でもアクセスできてしまうことに注意してください(2週間で自動的にデータは削除されます)。
この共有機能はセルフホストも可能になっているので、本格的に利用する場合はこちらの利用を検討してみても良いかもしれません。
https://www.promptfoo.dev/docs/usage/sharing#self-hosting
GitHub Actions との統合
実際に LLM アプリケーションを運用する場合は、評価のサイクルを CI に組み込みたいとなるのではないでしょうか。
ここでは GitHub Actions との統合方法について簡単に紹介します。
1. ワークフローの定義
promptfoo は公式で GitHub Actions との統合をサポートしています。
そのため、以下のようにして簡単に CI として組み込むことができます。
name: LLM Prompt Evaluation
on:
pull_request:
paths:
- 'prompts/**'
jobs:
evaluate:
runs-on: ubuntu-latest
permissions:
contents: read
pull-requests: write
steps:
- uses: actions/checkout@v4
- name: Cache promptfoo data
id: cache
uses: actions/cache@v4
with:
path: ~/.cache/promptfoo
key: ${{ runner.os }}-promptfoo-v1
restore-keys: |
${{ runner.os }}-promptfoo-
- name: Run promptfoo evaluation
uses: promptfoo/promptfoo-action@v1
with:
openai-api-key: ${{ secrets.OPENAI_API_KEY }}
github-token: ${{ secrets.GITHUB_TOKEN }}
prompts: 'prompts/**/*.json'
config: 'prompts/promptfooconfig.yaml'
cache-path: ~/.cache/promptfoo
結果は Pull Request に対するコメントとして出力されます。
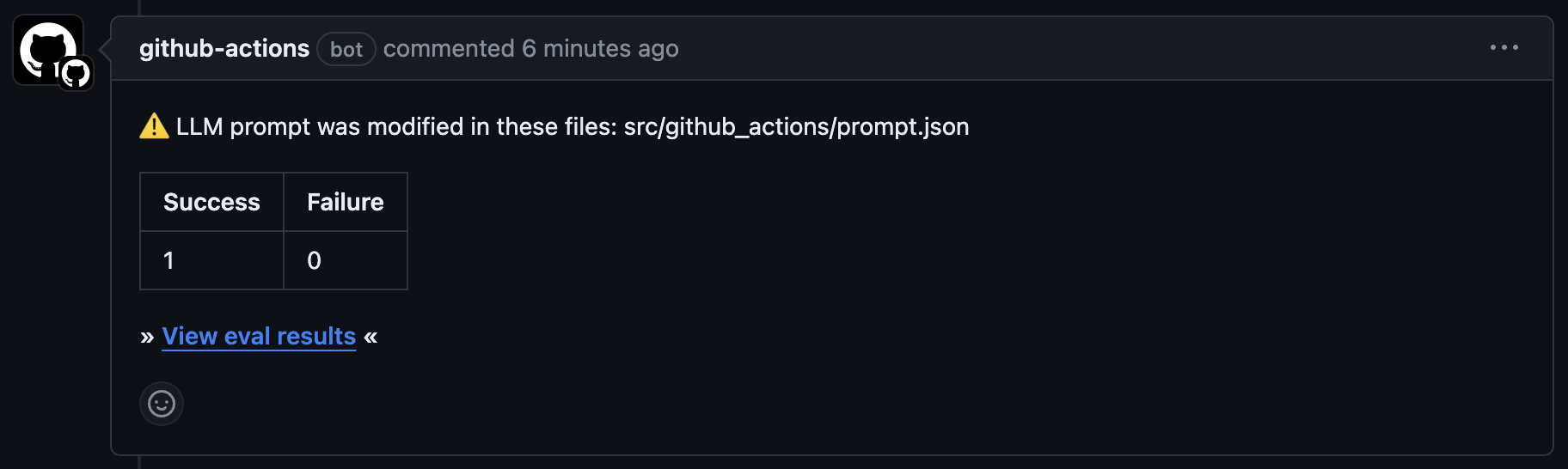
※「使い方 (CLI) > テストケースの定義 > 定義例」の定義ファイルとは別のものを実行した結果です
2. 評価の共有
CLI と同様に、GitHub Actions でも評価の共有がサポートされており、デフォルトで共有 URL が発行されるようになっています。
これは、no-share オプションを使うことで無効化することもできます。
3. その他の統合
promptfoo は CLI だけではなく npm パッケージも提供しています。
そのため、Jest や Mocha/Chai などのテストフレームワークに組み込む形で評価することも可能になっています。
詳しくは公式の Integrations を見てみてください。
まとめ
生成 AI の分野は進化がものすごく速く、各社の競争も激化しています。
そのため、promptfoo のようなツールを使用し、モデルの比較や開発プロセスの効率化を図ることも重要な要素の一つではないでしょうか。
promptfoo 自体は比較的新しいもので発展途上な部分もあるとは思いますが、導入の容易さ、豊富なプロバイダ選択肢、CIへの統合の容易さ、そして高度なカスタマイズ性を考慮すれば、十分に採用を検討する価値はあるのではないかと思います。